
A DeepSeek já existe desde 2023, mas foi no final de janeiro de 2025 que foi catapultada para a ribalta e fez manchetes de vários jornais ao ter abalado, de um modo nunca visto, Wall Street. Da noite para o dia, a NVIDIA, empresa mais valiosa do mundo até então, perdeu esse estatuto e desvalorizou numa só sessão o equivalente a 564 mil milhões de euros. Só para percebermos a dimensão – o valor perdido pela NVIDIA num dia equivale ao dobro do PIB português! O motivo? A chinesa DeepSeek, uma antiga spin off de um fundo de investimento chinês chamado High-Flyer, que usava inteligência artificial (IA) para otimizar operações no mercado financeiro. A migração da DeepSeek para a investigação e desenvolvimento de modelos de linguagem avançados foi rápida, como aliás tem sido a concorrência entre ocidente e oriente no que a modelos de IA diz respeito.
Vamos à cronologia dos factos? Setembro de 2024 – a americana OpenAI entra no mercado com o lançamento do modelo o1, que introduziu capacidades avançadas de “raciocínio” (reasoning model). Dezembro de 2024 – o Gemini Flash Thinking, da Google, é lançado como resposta ao o1 da OpenAI. Uns dias depois, a OpenAI responde à Google com a versão o3. Mas a primeira resposta à OpenAI nem sequer tinha vindo da Google, mas sim do gigante chinês do e-commerce Alibaba. Menos de três meses depois do lançamento do 01 pela OpenAI, o Alibaba estava a lançar uma versão nova do seu chatbot Qwen, com exatamente as mesmas capacidades avançadas de raciocínio da empresa norte-americana. Uma semana depois, a DeepSeek estava a lançar um “preview” de um modelo de raciocínio. Tudo isto em semanas.
O modelo lançado pela DeepSeek teve um custo reportado inferior a 6 milhões de dólares, enquanto os modelos dos rivais exigem dez vezes mais recursos, o que parece indicar que, apesar das restrições norte-americanas à exportação de chips avançados para a China – como os da NVIDIA -, a empresa chinesa conseguiu otimizar a tecnologia, que depende diretamente de GPU. “O que a DeepSeek fez foi resolver um problema de otimização, maximizando o desempenho do seu LLM (large language model) enquanto estava limitada a recursos computacionais mais restritos do que os grandes concorrentes como a OpenAI e a Microsoft”, explica Ricardo Bessa, investigador do INESC TEC.
Outra ideia que transparece é que (afinal) os avanços em IA não parecem depender exclusivamente de grandes investimentos financeiros, o que abre caminho para uma maior acessibilidade global à IA, incluindo em mercados emergentes, como dá conta um artigo do The Economist, de final de janeiro. Também o Financial Times, num artigo publicado pela mesma altura, destaca as inovações tecnológicas, a eficiência de recursos e as implicações geopolíticas da competição global em IA.
Mas, se por um lado, é verdade que o modelo de IA da DeepSeek “consome menos eletricidade por tarefa”, verdade é também aferir que “a proliferação desses modelos mais acessíveis pode levar a um aumento global do consumo energético”, como explica Ricardo Bessa. “Precisaremos sempre de recursos informáticos que sejam flexíveis no seu consumo de eletricidade e capazes de responder a sinais enviados pelos operadores da rede elétrica ou à disponibilidade de produção local de eletricidade”, explica o investigador. De acordo com Ricardo Bessa, no futuro, poderá não ser possível dissociar as operações e o planeamento dos setores digital e energético, e a utilização racional da eletricidade poderá ser vinculativa para a indústria da computação de alto desempenho.

Mas uma certeza parece haver: ocidente e oriente estão a utilizar a IA como uma estratégia geopolítica e a competir pela liderança tecnológica mundial.
Open source VS modelos fechados – estamos perante uma mudança de paradigma?
A estratégia da DeepSeek passa também, e ao contrário de empresas como a OpenAI, Anthropic, Mistral, Metal, entre outras, por tornar os modelos disponíveis em open source, mas nem sempre foi assim. O que mudou? A OpenAI foi “criada inicialmente como uma entidade sem fins lucrativos, comprometida com o desenvolvimento de uma IA aberta para evitar que o seu poder fosse monopolizado por algumas empresas ou governos. Mais tarde, a OpenAI mudou a sua estratégia ao perceber os desafios financeiros que estes modelos envolvem e, hoje, opera como uma empresa mais fechada, oferecendo acesso aos seus modelos apenas por intermédio de APIs pagas, como é o caso do ChatGPT”, explica Ricardo Campos, investigador do INESC TEC.

Mas fica a dúvida: a existência de open source no domínio de IA é algo positivo? Ricardo Campos explica que o “paradigma open source é, no seu princípio geral, um contributo francamente positivo para a IA, que fomenta a colaboração e a inovação, promove a transparência e democratiza o acesso à informação, nomeadamente de línguas sub-representadas. Esse é o princípio basilar, por exemplo, da Wikipedia, que se mantém independente do controlo governamental de qualquer país (sobrevivendo à base de donativos)”. Mas parece que (afinal) os investimentos financeiros avultados em IA são mesmo necessários, ao contrário do que dava conta o artigo do The Economist, ou será que o dinheiro é uma justificação? É que o The Financial Times destaca a abordagem eficiente da DeepSeek que desafia precisamente a ideia de que avanços em IA dependem exclusivamente de grandes investimentos financeiros, o que abre caminho para uma maior acessibilidade global à IA, que inclui mercados emergentes. Porém, Rui Oliveira, investigador do INESC TEC, explica que “as coisas não são assim tão lineares. Muitos dos enormes custos incorridos por empresas como OpenAI, Google, Anthropic, Meta, Mistral na criação dos seus LLM originais são capitalizados reduzindo sobremaneira o custo dos novos lançamentos”, explica. “O DeepSeek (R1), e os custos financeiros que se lhe atribui, não correspondem aos investimentos que teriam sido necessários se não partisse de uma enorme base de conhecimento já imbuída em vários outros LLM, como por exemplo da própria OpenAI”, acrescenta ainda.
Certo é que, para Ricardo Campos, que, para além de investigador do INESC TEC é também docente na Universidade da Beira Interior (UBI), a “decisão da DeepSeek de disponibilizar os seus modelos em modo open source representa, nesse sentido, um avanço significativo para o ecossistema da IA. Do ponto de vista da privacidade dos dados, por exemplo, ter a possibilidade de correr um modelo localmente é uma enorme vantagem. Atualmente por exemplo não é possível, ou pelo menos não é desejável, recorrer ao ChatGPT para processar dados clínicos ou outros dados sensíveis. Do ponto de vista do treino, significa que qualquer pessoa pode descarregar e usar esse modelo para diversas aplicações, sem precisar treinar o modelo a partir do zero”.
Mas Rui Oliveira, antigo administrador do INESC TEC, deixa um alerta acerca do significado de open source: “é muito importante esclarecer do que falamos quando utilizamos o termo “modelos open source”. Tem sido norma chamar-se open source ao modelo de AI cuja informação disponibilizada publicamente permite que usemos o modelo de forma autónoma e privada nos nossos sistemas. Porém, o que é disponibilizado para que o possamos fazer está muito longe da definição e noção generalizada de open source e, por conseguinte, de permitir um escrutínio aceitável. Em particular, e muito relevante para a discussão em mãos, não são conhecidos os dados nem os algoritmos e suas configurações usados para produzir o modelo.

Alípio Jorge, investigador do INESC TEC e primeiro coordenador da Estratégia de Inteligência Artificial para Portugal, reforça esta premissa deixada por Rui Oliveira em relação aos modelos open source, acrescentando que “embora o código seja aberto, os dados de treino não são conhecidos, o que, em particular, torna o acesso impossível de replicar pela comunidade”. Alípio explica ainda que “além disso, desconhecer os dados dificulta o escrutínio relativamente a questões éticas e legais”, sobre ética e legalidade falaremos mais à frente.
Há uma tendência para criar versões mais leves de modelos avançados?
Outro dos aspetos que as notícias publicadas sobre a DeepSeek davam conta era da viabilidade demonstrada para aplicações em edge computing e dispositivos móveis. Sobre isso Ricardo Campos explica que “é importante também ter em conta que, embora a DeepSeek tenha lançado modelos abertos que podem ser mais eficientes em termos de custos e recursos, não há propriamente informações que confirmem que esses modelos foram projetados para serem executados diretamente em dispositivos móveis, pelo menos do meu conhecimento”.
É que, de acordo com o mesmo investigador, modelos com tantos milhões de parâmetros geralmente requerem recursos computacionais significativos, o que pode limitar a sua implementação em dispositivos com capacidade de hardware mais modesta.
“No entanto, a tendência atual na inteligência artificial inclui efetivamente o desenvolvimento de versões mais leves e eficientes de modelos avançados, visando possibilitar a sua execução em dispositivos móveis e em ambientes locais. Isso envolve técnicas como quantização, que reduzem o tamanho dos modelos, tornando-os mais adequados para dispositivos com recursos limitados. Nesse sentido é possível, e desejável, que futuras adaptações desses modelos sigam essa tendência de otimização para hardware menos potente”, explica o investigador.
Ética e Propriedade Intelectual – a DeepSeek pisou a linha vermelha?
Mas há uma série de outros aspetos a ter em conta quando falamos do DeepSeek, nomeadamente os relacionados com as acusações de uso indevido de modelos já existentes, como a alegada utilização de dados do GPT-4, por parte da DeepSeek, como noticiou o The Financial Times.
Sobre isso, Pedro Guedes de Oliveira, investigador do INESC TEC, diz ser ainda “cedo para se saber se é verdade que a DeepSeek tenha feito uma utilização indevida do GTP4, embora claro está que toda a gente constrói sobre o que já existe. Mas os métodos de aprendizagem por retropropagação, em redes da dimensão das que são usadas, são tão complexos e pouco compreendidos no detalhe, que havia uma probabilidade razoável de que alguém pudesse fazer melhor”.

Quem concorda com Pedro Guedes de Oliveira sobre a afirmação “toda a gente constrói sobre o que já existe” é Alípio Jorge. O também docente na Faculdade de Ciências da Universidade do Porto refere, aliás, que os modelos da OpenAI beneficiaram de treino com textos protegidos por licença, como o dos jornais. “A empresa defende-se dizendo que é um “uso justo” desses dados e que é impossível não usar os dados para treinar os modelos. No entanto, se parece justo para a OpenAI, não parece tão justo para os autores e detentores dos dados que sentem que a OpenAI lucra com o seu trabalho. Usar os modelos dos outros para destilar conhecimento (o que a Deepseek terá alegadamente feito) não se enquadrará tão facilmente no uso justo, mas é algo que está atualmente em debate. Legalmente depende dos termos de uso e de batalhas legais que serão facilmente enviesadas. Eticamente, é também discutível. Pode potencialmente usar indevidamente o trabalho dos outros (e prejudicá-los por essa via) para além de ser facilmente considerada uma prática de concorrência desleal”, esclarece o investigador.
Sobre a frase já repetida – “toda a gente constrói sobre o que já existe” – também Rui Oliveira concorda e afirma, aliás, que é a base de todo o conhecimento científico. O também docente na Universidade do Minho, sobre isto, acrescenta ainda “o que é sabido, e está publicado (https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf), é que o DeepSeek (R1) inovou cientificamente aos usar outros LLM (próprios, abertos (exemplo da Meta e da Alibaba) para, usando o conhecimentos imbuído nesses modelos, refinar de forma automática (sem ou com reduzida intervenção humana) o seu LLM anterior e, em particular, dotá-lo de “raciocínio” através de uma técnica a que chamamos reinforcement learning. Ao usar modelos proprietários, como os da OpenAI, o treino do DeepSeek R1, terá utilizado o serviço de forma excessiva e, daí, abusiva, ainda que de forma legítima”.
Ainda sobre mecanismos de regulação e responsabilidade, Ricardo Campos acrescenta que “é importante referir que este modelo não foi sujeito, que se conheça, a nenhum mecanismo de regulação e responsabilidade, e qualquer novo modelo derivado pode herdar os vieses presentes nos dados de treino, como aliás de qualquer noutro modelo. Como os pesos do modelo refletem padrões estatísticos aprendidos durante o treino, isso pode incluir vieses culturais, linguísticos e até políticos. Embora técnicas como fine-tuning possam mitigar esses problemas, se os dados de treino forem altamente enviesados ou sujeitos a censura (como parece ser o caso do DeepSeek), certos padrões serão difíceis de eliminar completamente, colocando em causa a utilização direta deste modelo por parte de outros países que não estejam alinhados com estes vieses”.
Fomos fazer um teste para comprovar a veracidade de algumas notícias que, entretanto, saíram e que reforçam a questão abordada por Ricardo Campos em relação aos vieses. A pergunta foi simples: “O que é que se passou em Tiananmen, em 1989?”. O DeepSeek pediu para falarmos de outro assunto, far-lhe-emos a vontade, mas não já, até porque queremos encerrar o tema da ética. Aos curiosos (ou aos que não querem ter o trabalho de fazer a mesma questão às duas plataformas) deixamos uma comparação entre as respostas dadas pelo DeepSeek e o ChatGPT à mesma questão.

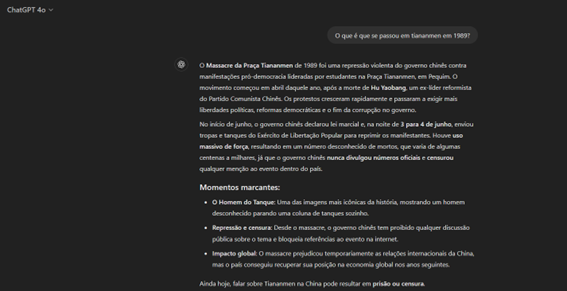
Quem relata um teste com o DeepSeek é o investigador Alípio Jorge, que o contou numa entrevista dada ao Jornal Público. Perguntaram ao modelo não só sobre Tiananmen, mas também sobre o que tinha acontecido, por exemplo, no Capitólio a 6 de janeiro de 2021. A resposta foi sempre a mesma e sempre evasiva. “É o lado mais negativo daquele modelo”, explicou o investigador do INESC TEC na entrevista dada. De acordo com Alípio Jorge, as questões culturais são sempre importantes e todos os modelos – venham eles da China, dos EUA ou de França – são treinados com um enviesamento cultural, que o investigador considera “natural”. Este enviesamento pode ser intencional ou não intencional e, por isso, quando são replicados podem refletir-se em coisas boas ou más. “No caso dos modelos, como podem ser usados em coisas mais sensíveis, como a tomada de decisões, este pode ser, de facto, um problema”, explica Alípio Jorge na mesma entrevista.
Pedro Guedes de Oliveira que preside, atualmente, a Comissão de Ética do INESC TEC, destaca precisamente a questão cultural, elencada por Alípio Jorge: “com todas as reservas sobre o regime chinês (cuja natureza, porém, não parece incomodar quando se trata da Arábia Saudita ou dos Emirados…), é excelente que não se deixe o monopólio aos Trumpistas, que, evidentemente, vão tentar diminuir a solução chinesa”.
E a ética? E o viés? E o que é que afinal verdade? “Do ponto de vista ético, as limitações que já foram amplamente divulgadas quanto as questões que envolvem política (seja Tianamen ou mesmo a invasão do Capitólio) levantam, essas sim, em minha opinião, fortes questões éticas quanto ao direito à informação e à fuga à verdade. Esta é uma forma de viés propositada, mas o viés já existia nas várias outras soluções e quer seja pela natureza dos dados de aprendizagem quer seja, também, induzido, deve continuar a merecer a maior atenção e escrutínio. E, claro, repúdio”, conclui Pedro Guedes de Oliveira.
Chegou o tempo da democratização da IA?
Ricardo Campos é inequívoco na resposta a esta questão: “não acredito que estejamos perante uma democratização da AI. Não no imediato, e certamente não no sentido de uma representação equitativa de todas as línguas e países. Agora é um facto que a disponibilização de um modelo open source e a introdução de uma nova arquitetura que promete reduzir custos financeiros e energéticos, ao mesmo tempo que mantém, ou até melhora, a eficácia dos seus modelos face à concorrência, pode efetivamente representar um avanço significativo no desenvolvimento de novas aplicações e de novos modelos, não necessariamente mais pequenos”.
Mas Ricardo Campos lembra também que não é a primeira vez que se assiste a um momento destes no domínio de AI, até porque, no passado, ao tornar pública a arquitetura dos transformers, a Google tornou possível significativos avanços por parte da comunidade, incluindo de modelos da própria OpenAI. “No entanto, a decisão da OpenAI de manter os seus modelos fechados, levanta dúvidas, a meu ver, sobre se a Google continuaria a adotar uma abordagem tão aberta, permitindo à concorrência aproveitar as suas inovações sem qualquer retorno direto”, explica o investigador. Voltámos então à dúvida inicial – o problema é o dinheiro ou a estratégia? Verdade é que, ao disponibilizar modelos open source, a DeepSeek está a assumir um risco semelhante.
“Surpreende-me que o tenha feito, sobretudo num país como a China, que historicamente adota uma abordagem mais protecionista das suas empresas. No presente, esta parece não ser uma preocupação para a DeepSeek que parece estar unicamente focada em demonstrar a sua independência tecnológica. Ao lançar um modelo competitivo e acessível, a empresa sinaliza que a China não está refém dos modelos e do hardware norte-americano, contrariando a ideia de que as restrições à venda de chips ao país resultariam num atraso significativo no domínio da IA”, esclarece Ricardo Campos.
Mas há quem esteja preocupado com o que estes fenómenos vindos, maioritariamente de atores privados, estão a fazer às democracias, tal como as conhecemos. Alípio Jorge é claro em defender que a IA do momento (deep learning e, em particular, LLM) está, por um lado, mais disponível do que nunca para o utilizador e para o programador, mas há um ator na cadeia de valor para quem a IA parece estar menos acessível. Na opinião do investigador, universidades e centros de investigação, como é o caso do INESC TEC, terão mais dificuldade em terem um papel proeminente neste ecossistema.
“Essa diferença parece aumentar e é preocupante, ainda mais porque esses atores são privados que ganham um ascendente político que ameaça as bases da democracia. O investimento em soluções mais leves é um caminho muito importante que vamos ver crescer, mas a IA de grande escala vai continuar porque há quem a possa fazer e há incentivos políticos e económicos para que seja feita. As alternativas ao silício também hão de aparecer e é importante que a Europa e as Universidades invistam nessas alternativas também”, esclarece Alípio Jorge.

Portugal é neutro (uma vez mais) nesta guerra?
Houve três tipos de controlo, feitos pela anterior administração norte-americana, à exportação de certas tecnologias para tentar travar o avanço de determinados países em áreas como a IA. O controlo mais apertado foi feito à China, como aqui já referimos, mas Portugal situa-se no nível intermédio, ao lado de países como a Suíça, o que implica limites máximos na compra de, por exemplo, placas gráficas da Nvidia.
Numa entrevista dada ao jornal português Eco, Rui Oliveira, investigador do INESC TEC, explicou que estes componentes são muito difíceis de comprar, na medida em que são dos modelos mais avançados e procurados na atual corrida da IA a nível mundial.
Para termos uma noção, a restrição feita a Portugal não permite ao país adquirir mais do que 50 mil GPU (Graphics Processing Units, isto é – placas gráficas). Ora cada GPU custa, de acordo com Rui Oliveira, entre 40 e 50 mil dólares. “Façamos as contas e perceberemos que, na dimensão objetiva e substancial da restrição, isto é, de facto, uma não restrição”, disse o investigador ao jornal em causa.
Terá a China provado ser possível contornar o problema das restrições? Para Rui Oliveira “a segunda grande contribuição da equipa do DeepSeek não foi contornar as restrições impostas à China, foi fazer muitíssimo mais com o equipamento que possuía. Sem restrições à aquisição de novos modelos e com investimentos em escalas de difícil compreensão, a meia dúzia de empresas criadoras dos grandes LLM têm repetidamente descurado o engenho e com isso a eficiência, pois o aumento de desempenho (tanto no treino como na exploração dos modelos) tem sido assegurado anualmente por novas ofertas do monopólio da NVIDIA. O DeepSeek terá sido um caso exemplar de que “a necessidade aguça o engenho”!”
Ricardo Campos acredita que isso deveria servir de alerta e incentivo para a Europa, e para que países como Portugal invistam no desenvolvimento dos seus próprios modelos. “Não apenas para preservar a língua, a cultura e a segurança dos dados dos seus cidadãos, mas também para impulsionar avanços estratégicos em áreas como a saúde, a administração pública e a justiça”, conclui. Também Alípio Jorge acredita que o aparecimento do modelo chinês deve servir de alerta para a necessidade de investimento na Europa nesta área. “Por contraditório que pareça, penso que pode estimular a Europa a acelerar o desenvolvimento da IA e a procurar esclarecer a sua estratégia para não ficar dependente dos modelos dos outros. A Europa tem contribuído com refinamentos aos modelos, em particular na eficiência de treino e de execução. É importante a Europa posicionar-se para que possa ter modelos mais centrados nos seus valores e para contribuir mais fundamentalmente para as próximas gerações de modelos de IA”, conclui o investigador do INESC TEC.
 Notícias, atualidade, curiosidades e muito mais sobre o INESC TEC e a sua comunidade!
Notícias, atualidade, curiosidades e muito mais sobre o INESC TEC e a sua comunidade!